cockroachdb severless 解读
2022-05-17
云原生数据库架构系列的第二篇,这次的内容是 cockroachdb 是如何实现 serverless 的。对这一篇博客的解读。
其实是这是非常重要的一篇,可以断言,像这种面向企业服务的 database 公司,未来一定是 cloud 的时代。做头部大客户的模式,随着客户普及率越来越高,市场会饱和;虽然每一单的客单价较大,但是每一单都不好拿下,竞争激烈;尤其是后续的服务跟进,服务大客户是一个并不 scalable 的事情。 DBA/销售/研发,这些都需要成本的投入。数据库的 scale 能力决定了这个产品的上限,而一家公司能用多少人服务多少客户的 scale 能力,决定了公司营收的上限。
所以怎么样破局呢?上云。把数据库的服务化,降低门槛,让即使很小的客户也能够用上,这样子长尾的市场就打开了。做国际化的市场,而不是在仅仅国内市场内巻。如果做成单个数据库,就可以支持全球的数据存储服务,那么运维就只需要运维一个数据库,虽然难度很高,但是运维的成本是降低的。 这里的 severless ,也就是托管/多租户。cockroachdb 走在前面了,这一点友商是值得去学习的。
背景说完,进入正题。
severless 之后,客户不再需要考虑机器的问题,只为真正的使用付费,这个是可以降低成本的。假设是 tidb 的集成,用户想试用,需要部署的组件,至少一个 pd,一个 tidb,三个 tikv,再有周边的 prometheus,监控的 grafana,数据同步备份之类的工具组件,这就需要好多个虚拟节点了。 即使 4 cpu 的机器,这个试用的成本都是挺高的。不管用不用,即使集群空转,也是在烧钱。
而 serverless 卖服务的形式,一个集群就可以服务"无穷"个租户,只要没有实际的使用,并不会产生成本。多增加一个租户,它的边际成本是零。所以这个模式是 scalable 的。
跟很多分布式数据库一样,cockroachdb 在整个架构上,分为计算层和存储层。存储层管理 key-value 存储,支持分布式事务这些东西。key-value 是有序的,然后逻辑上按 range 进行划分,一段 range 的数据再物理上分布到具体的存储节点上面。每一块 range 的 key-value 数据会有多份副本,这样在分布式环境下,部分副本挂掉的时候数据不会丢失。
多租户的时候如何处理呢?假如共享整个计算层和存储层,资源隔离是特别难做的。因为 SQL 可以很复杂,单个 SQL 可以把整个集群的资源都吃尽,如果同进程供不同租户使用,服务质量得不到保证。而如果每个租户独享各自的计算层和存储层,也就是回到了每个租户一套集群的模式,前面也说了问题:成本下不来。所以最好的方式是,独享计算层,共享存储层。上层的 SQL 是租户之间物理隔离的,下面的 kv 存储是由所有租户去共享的。
共享存储层之后,需要区分哪些数据是属于哪个用户的,cockroachdb 使用的方法是在 key 的编码中添加了 tenant-id,多租户模式下,SQL 的表的数据映射成 kv 数据,最终的编码是 /tenant-id/table-id/index-id/key 这样子的。
这里有一个细节,是衡量资源的使用。每个租户不能够对存储层产生的负载太猛,而影响其它租户的服务质量。不过相对于 SQL 来说,kv 的使用模式相对简单,会在 kv 这一层对多租户衡量其它吞吐量并限制不要超过阀值。
cockroachdb 是用 k8s 来操作集群,k8s 集群里面有(多租户共享的)存储节点和每个租户独享的 SQL 计算节点。SQL 资源的使用可以通过 k8s 的 pod 来控制。
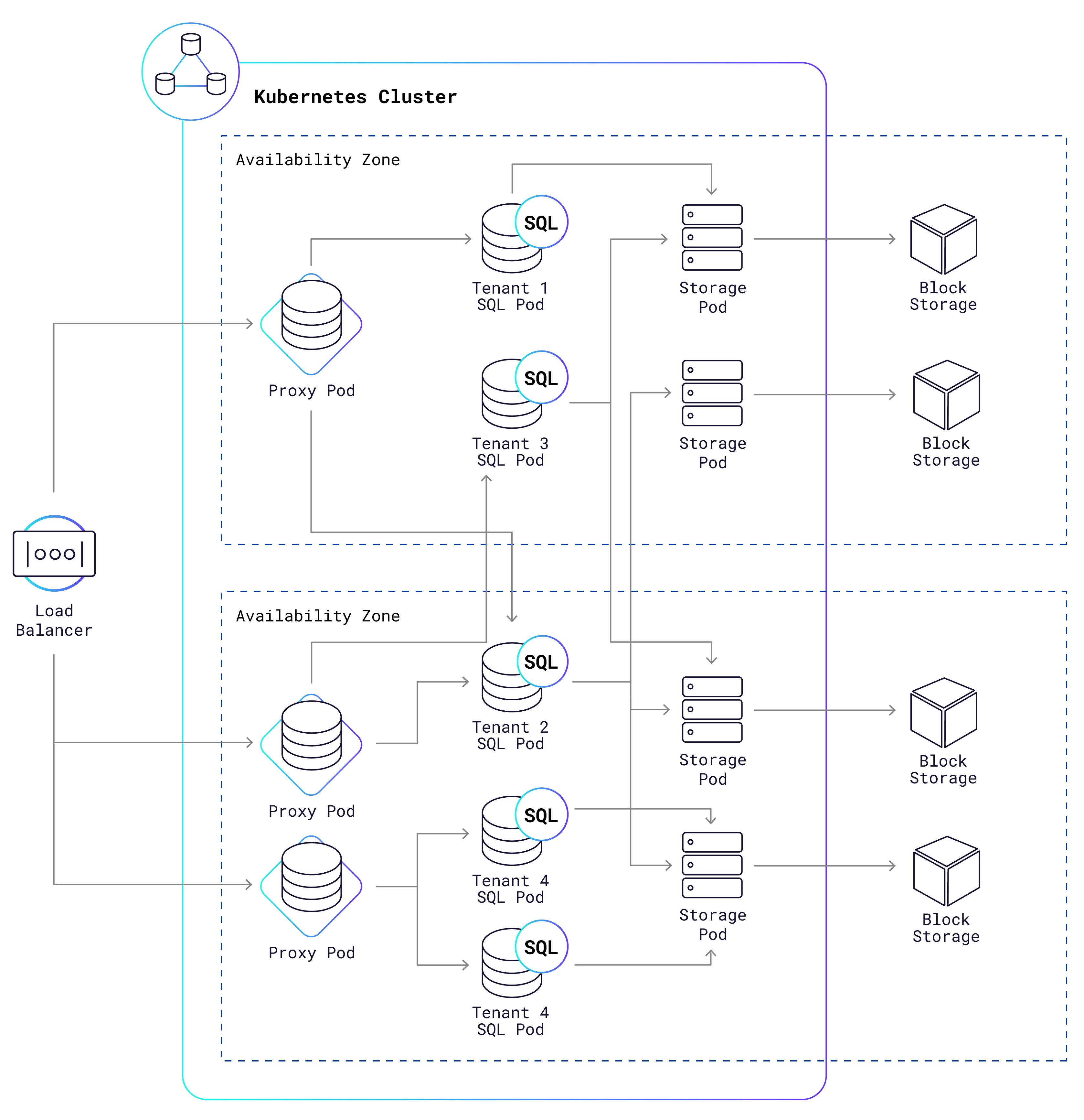
其中有个角色是 proxy 节点。其实 proxy 节点的角色就是上一篇里面讲的 session manager,它可以把租户的请求路由到正确的 SQL 节点上面;它可以处理 SQL 节点的负载均衡;一个很关键的一点,它还可以处理 SQL 节点重启/升级之类的对应用层无感知。
SQL pod 是由 tenant 独享的,这样可以做到安全性的隔离。proxy pod 是可以多 tenant 共用的,它做的只是 forward 请求到具体的 SQL pod 上去。
计算节点无状态,这意味着 SQL pod 可以随用随起,也就是说,当某个 tenant 没有流量时,完全可以把它的 SQL 节点停下关掉,需要的时候再动态起来。不过如果是整体的 SQL 的 VM 停掉,再起来需要时间,所以 cockroachdb 的做法是维护一些备用的 SQL 节点,随时准备变成某个租户的 SQL pod。
来看 scale 能力,有的租户很小,而有的租户可能需要大量的 scale。大部分租户的 workload 可能就是零,cockroachdb 提供给开发者去试用,这个不用收钱。当集群规模够大时,只要没有真正的负载,这个架构上单个租户的成本其实就是零。 对于大客户,如何扩容呢?在 SQL pod 这一层,是根据每秒的 traffic load 来判断的,当需要时,可以根据租户的 traffic load 完成在秒级的扩缩容,这样很好地响应极高的突发流量。而负载没了之后,不活动的 SQL pod 又可以停掉,或者放到池子里,变成新的 pod 去服务其它的 tenant。
当然,这种只是理想中的情况,因为 SQL pod 无状态,比较好处理突发流量。而现实是,KV pod 还是需要面对这种突发流量,而它是有状态的,并不能那么快的 scale。 SQL pod 的自动扩容取决于最近 5 分钟的平均和峰值 CPU 使用率,从平均 CPU 可以看到资源使用情况,而峰值 CPU 可以应对突发流量。注意,这一切在 cockroachdb 都是自动完成的,不需要人为介入。它有个 autoscale 的监控组件,会控制 k8s pod 去处理这种扩缩容操作。
小租户试用时,主要是 SQL pod 的成本,由于他们的数据量很少,存储 pod 的本成是可以忽略不计的。只要没什么负载时,SQL pod 可以停掉,随用随起,确实是 severless,牛X!