SQL优化器庖丁解牛篇(二)
2018-02-27
逻辑算子
发现对于零基础的读者,如果不先讲算子,后面都没法讲。所以还是先写一点。
- DataSource 这个就是数据源,也就是表。
select * from t里面的 t - Selection 选择,就是
select xxx from t where xx = 5里面的 where 过滤条件条件 - Projection 投影,也就是
select c from t里面的列 c - Join 连接,
select xx from t1, t2 where t1.c = t2.c就是把 t1 t2 两个表做 join,这个连接条件一个简单的等值连接。join 有好多种,内关联,左关联,右关联,全关联...
选择,投影,连接(SPJ) 是最基本的算子。
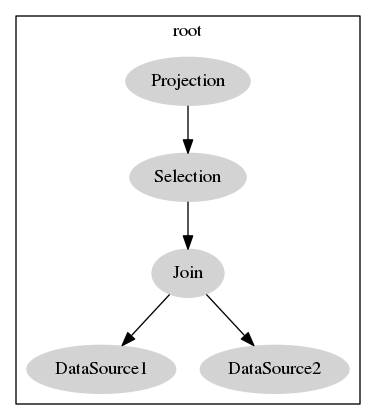
select b from t1, t2 where t1.c = t2.c and t1.a > 5
变成逻辑查询计划之后,t1 t2 对应的 DataSource,负责将数据捞上来。上面接个 Join,将两个表的结果按 t1.c = t2.c 连接,再按 t1.a > 5 做一个 Selection 过滤,最后将 b 列投影。下图是未经优化的直接表示:
- Sort 就是
select xx from xx order by里面的 order by,排序。无序的数据,通过这个算子之后,向父结点输出有序的数据。 - Aggregation 就是
select sum(xx) from xx group by yy的 group by yy,按某些列分组。分组之后,可能带一些聚合操作,比如 Max/Min/Sum/Count/Average 等,这个例子里面是一个 sum。 - Apply 这个是用来做子查询的,后面再讲它的作用。
逻辑优化做的事情,就是把 SQL 转成由逻辑算子构成的查询计划,这颗树的结构会被变来变去,使得执行时代价尽量的小。
物理算子跟逻辑算子的不同之处,在于一个逻辑算子可能对于多种物理算子的实现,比如 Join 的实现,可以用 NestLoop Join,可以用 HashJoin,可以用 MergeSort Join等。比如 Aggregation,可以用 Hash 或者排序后分组不同的做法,比如 DataSource 可以直接扫表,也可以利用索引读数据。
列裁剪
列裁剪的思想是这样子的:对于用不上的列,没有必要读取它们的数据,去浪费无谓的IO。
比如说表 t 里面有 a b c d 四列。
select a from t where b > 5
这个查询里面明显只有 a b 两列被用到了,所以 c d 的数据是不需要读取的。那么 Selection 算子用到 b 列,下面接一个 DataSource 用到 a b 两列,剩下 c 和 d 都可以裁剪掉,DataSource 读数据时不需要将它们读进来。
算法是自顶向下地把算子过一遍。某个结点需要用到的列,等于它自己需要用到的列,加上它的父亲结点需要用到的列,将没用到的裁掉。从上到下的结点,需要用到的列越来越多。
主要影响的Projection,DataSource,Aggregation,因为它们跟列更相关。Projection 里面干掉用不上的列。DataSource 里面裁剪掉不需要使用的列。
Aggregation 涉及哪些列?group by 用到的列,以及聚合函数里面用到的列。比如 select avg(a), sum(b) from t group by c d ,这里面 group by 用到的 c 和 d,聚合函数用到的 a 和 b。
Selection 就是看它父亲要哪些列,然后它自己的条件里面要用到哪些列。Sort 就看 order by 里面用到了哪些列。Join 里面,把 join 条件用到的各种列都要加进去。
通过列裁剪这一步操作之后,查询计划里面各个算子,只会记录下它实际需要用到的那些列。下一篇敬请期待!